Heterogeneous computer architectures with extensive use of hardware accelerators, such as FPGAs, GPUs, and neural processing units, have shown significant potential to bring in orders of magnitude improvement in compute efficiency for a broad range of applications. However, system designers exploring these non-traditional architectures generally lack effective design methodologies and tools to swiftly navigate through the intricate design trade-offs and achieve rapid design closure. While several heterogeneous computing platforms are becoming commercially available to a wide user base, they are very difficult to program, especially those with reconfigurable logics. To address these pressing challenges, our research group investigates new applications, programming models, algorithms, and tools to enable highly productive design and implementation of application- and domain-specific computer systems. Our cross-cutting research intersects CAD, machine learning (ML), compiler, and computer architecture. In particular, we are currently tackling the following important and challenging problems:
Algorithm-Hardware Co-Design for Machine Learning Acceleration
Our group is investigating various accelerator architectures for compute-intensive machine learning applications,
where we employ an algorithm-hardware co-design approach to achieving both high performance and low energy.
More specifically, we are exploring new layer types in deep neural networks that map very efficiently to FPGA/ASIC
accelerators. Examples include channel gating [C59],
precision gating [C61],
unitary group convolution [C57],
and outlier channel splitting [C56].
We are also among the first to design and implement a highly efficient binarized neural network (BNN) accelerator,
which is demonstrated on FPGAs [C35]
[W3]
[C72],
and included as part of the 16nm 385M-transistor Celerity SoC (opencelerity.org)
[C39]
[W4]
[J8].
More recently, we developed GraphZoom [C62]
and FeatGraph [C69] to accelerate graph learning
models on CPUs and GPUs. In addition, we are developing a suite of realistic benchmarks for software-defined FPGA-based
computing [C42]. Unlike previous efforts, we aim to
provide parameterizable benchmarks beyond the simple kernel level by incorporating real applications from emerging domains.
Besides improving the performance of ML applications, we also develop ASIC designs to accelerate sparse linear algebra
kernels. Specifically, we are the first to propose a generalized accelerator for efficiently computing both dense and sparse tensor
factorization with a new sparse storage format, i.e., Compressed Interleaved Sparse Slice (CISS)
[C60]. Also, we exploit the row-wise product with a
hardware friendly sparse storage format, i.e., Cyclic Channel Sparse Row (C2SR), for accelerating the SpGEMM kernel
[C66].
Software-Defined FPGA Acceleration
The latest advances in industry have produced highly integrated heterogeneous hardware platforms, such as the CPU+FPGA
multi-chip packages by Intel and the GPU and FPGA enabled AWS cloud by Amazon. Although these heterogeneous computing
platforms are becoming commercially available to a wide user base, they are very difficult to program, especially with
FPGAs. As a result, the use of such platforms has been limited to a small subset of programmers with specialized knowledge
on the low-level hardware details.
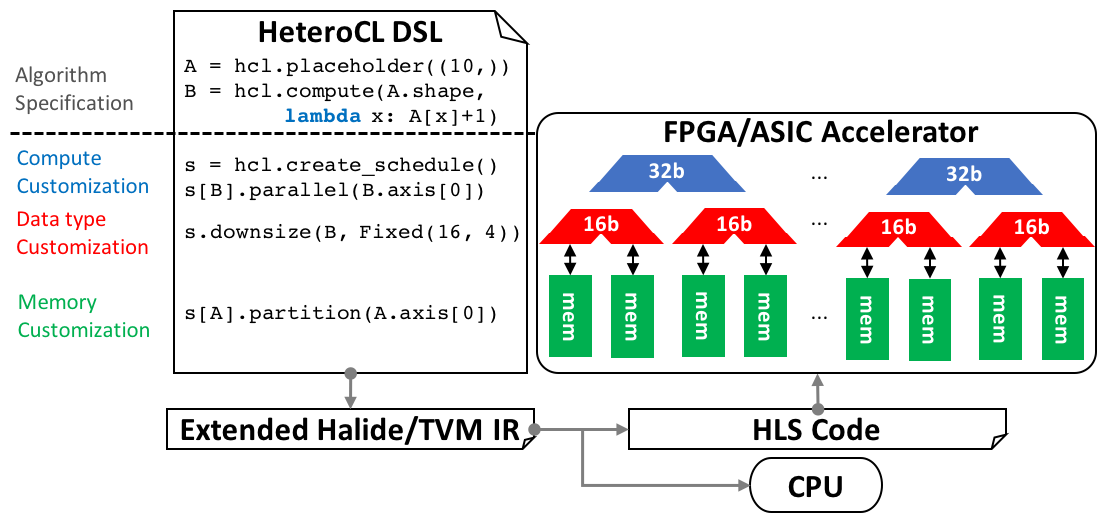
To democratize accelerator programming, we are developing HeteroCL, a highly productive multi-paradigm programming
infrastructure that explicitly embraces heterogeneity to integrate a variety of programming models into a single, unified
programming interface [C47].
The HeteroCL DSL provides a clean programming abstraction
that decouples algorithm specification from three important types of hardware customization in compute, data types, and
memory architectures. It further captures the interdependence among these different customization techniques, allowing
programmers to explore various performance/area/accuracy trade-offs in a systematic and productive manner. SuSy is another
programming framework composed of a DSL and a compilation flow that enables programmers to productively build high-performance
systolic arrays on FPGAs [C68].
Experimental results show that SuSy can describe various
algorithms with uniform recurrence equations (UREs) and generate high-performance systolic arrays by spatial optimizations.
For instance, the SGEMM benchmark written in SuSy can approach the performance of the manual design optimized by experts,
while using 30x fewer lines of code.
Recently, we started looking at accelerating data center networking stacks with FPGAs. We develop Dagger
[C73] - a further extension of specialized
programmable networking adapters designed specifically to offload end-to-end cloud Remote Procedure Calls (RPC)
stacks to reconfigurable hardware. Our programmable FPGA-based NIC features full networking offload up to the application
layer, reconfigurability, and closed coupling with the host processor over a memory interconnect. We show that the
combination of these three principles improves both end-to-end latency and throughput of cloud RPC stacks while providing
the same level of flexibility and abstraction as existing mainstream RPC systems based on software-only implementations.
Intelligent High-Level Synthesis
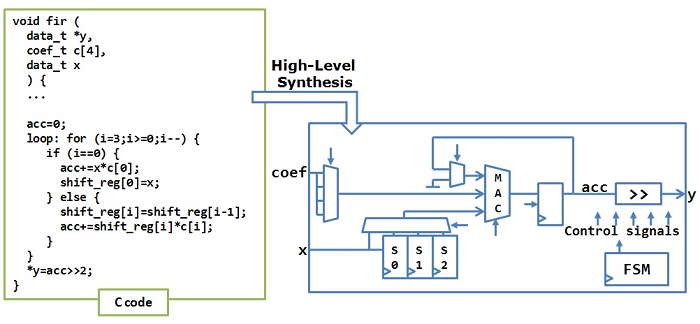
Specialized hardware manually created by traditional register-transfer-level (RTL) design can yield high performance
but is also usually the least productive. As specialized accelerators become more integral to achieving the performance
and energy goals of future hardware, there is a crucial need for above-RTL design automation to enable productive modeling,
rapid exploration, and automatic generation of customized hardware based on high-level languages. Along this line, there has
been an increasing use of high-level synthesis (HLS) tools to compile algorithmic descriptions (e.g., C/C++, Python) to RTL
designs for quick ASIC or FPGA implementation of hardware accelerators
[J5]
[J4].
While the latest HLS tools have made encouraging progress with much improved quality-of-results (QoR), they still
heavily rely on designers to manually restructure source code and insert vendor-specific directives to guide the synthesis
tool to explore a vast and complex solution space. The lack of guarantee on meeting QoR goals out-of-the-box presents a major
barrier to non-expert users. To this end, we are developing a new generation of HLS techniques that feature scalable cross-layer
synthesis [C25]
[C26] and exact optimization
[C43], complexity-effective dynamic scheduling
[C28]
[J7]
[C33], trace-based analysis
[C36], and information flow enforcement
[C46] to enable a radically accelerated and greatly
simplified hardware design experience, while achieving high performance and satisfying the security constraints.
Learning-Assisted IC Design Closure
A primary barrier to rapid hardware specialization is the lack of guarantee by existing CAD tools on achieving design closure in an
out-of-the-box fashion. Mostly, using these tools requires extensive manual effort to calibrate and configure a large set of design
parameters and tool options to achieve a high QoR. Since CAD tools are at least two orders of magnitude slower than a software compiler,
evaluating just a few design points could already be painfully time-consuming, as physical design steps such as place-and-route (PnR)
commonly consume hours to days for large circuits.
We believe there is a great potential for employing ML across different stages of the design automation stack to expedite design
closure by (1) minimizing human supervision in the overall design tuning process and (2) significantly reducing the time required to
obtain accurate QoR prediction for a given design point. Along these directions, we have demonstrated the efficacy of our approach by
applying ML to distributed bandit-based autotuning for FPGA timing closure
[C34]
[C48], resource prediction in FPGA HLS
[C44], operation delay prediction for FPGA HLS
[C67], and power inference for reusable ASIC IPs
[C54].